[title]前序[/title]
我记得我第一次写的P站爬虫是用易语言写的,还不错。也发到贴吧上面分享,后来看了百度云,有1000+的下载量。后来爬虫失效后,打算用python写,当时我听说是最著名的爬虫利器。
其实很久之前我也写了第一代基于python的P站爬虫,感觉还不错。大概6个月前吧,发现P站的PHP代码改了,导致之前旧的爬虫都失效了。好家伙,打算自己开python重新写一遍。
这次的爬虫目的就是让搜索页的图片全部爬下来。( ̄▽ ̄)~*
注意:刚刚入坑小白最好有一定的python基础,dalao请你随便。
[title]目前需要的Python库[/title]
下面我会举例要用到的库并说明一下其调用说明
import requests
#各种网络请求
from bs4 import BeautifulSoup
#从HTML文件中提取数据
import re
#切割文本
import json
#json解析
import os
#调用os.path.isfile判断文件是否存在
import codecs
#读取写入文件
from urllib import parse
#各种字串符格式转换
import threading
#多线程处理
#但是目前按照这破网速单线程就可以了[title]初始化一些必要的东西[/title]
下面是要初始化一些必要的数据类型和一些必要操作
#这个是用来定义保存在搜索界面上爬下的数据
class pixiv_href(object):
#作品ID
illustId = []
#作品页数
pageCount=[]
#搜索页URL
search_url = ""
#FLAG标记,下面会说有用途
_return = []
pixiv_href_data=pixiv_href()
#下载目录
downloadfile_data=""
#cookies数据
cookies_data=""
#下载使用的线程数,但是我们目前不用这个
#threads_number=1
#新建requests的会话控制
se = requests.session()[title]POST登录[/title]
首先得用python进行模拟登录,也就是我们接下来要说的POST登录。
有人问我:为什么要POST登录? :huaji15:
其实不用POSE登录也可以,因为在这里POST登录是用来过滤P站的书签的(也就是赞),你没登录是看不了的赞的次数,以免一些质量不怎么高的作品浑水摸鱼。
但是我发现不用登录返回作品界面的HTML代码居然和登录后返回的还不一样,淦!
进入P站登录页面后,按F12打开浏览器的开发者工具。
然后进入Network(网络)面板下,勾选Preserve log(保存日记),这样网页跳转的时候日记不会清除。
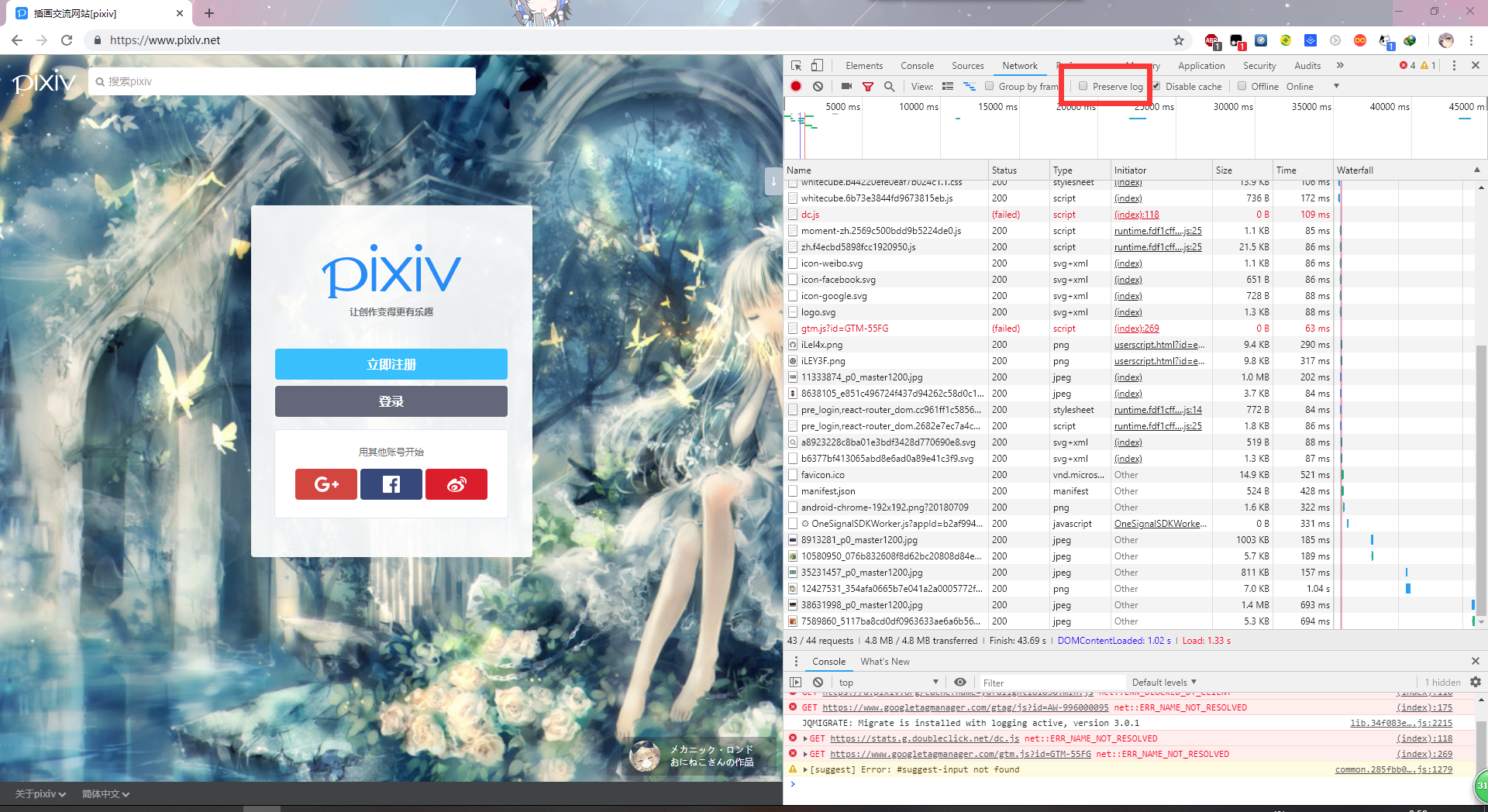
输入账号密码后点击登录,这时你发现右边突然出现一个POST请求,我猜大概是登录请求了。进入查看form data(表格数据)。
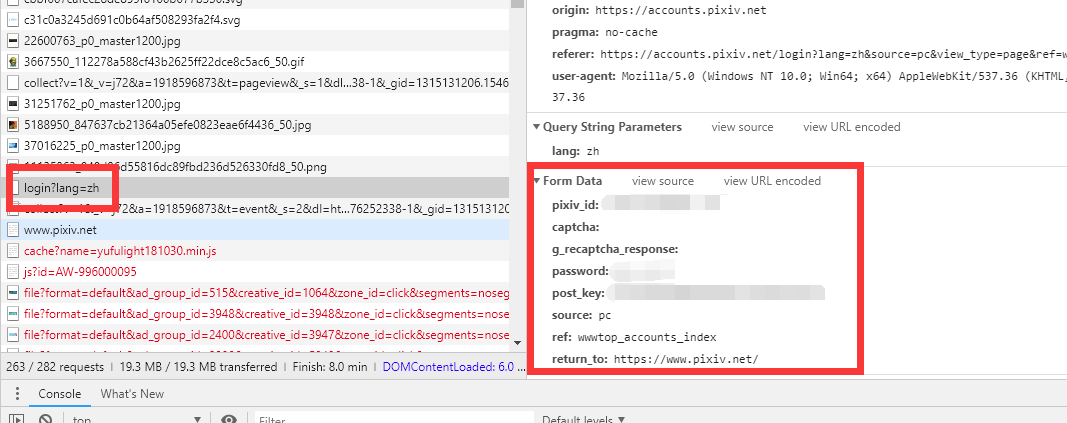
好家伙,发现DATA里面的密码连加密都懒得加,直接以明文的形式发送了。正好省得我们功夫去翻脚本写加密。
问题来了,post_key是哪里来的,而且每次刷新都不一样。 :yinxian:
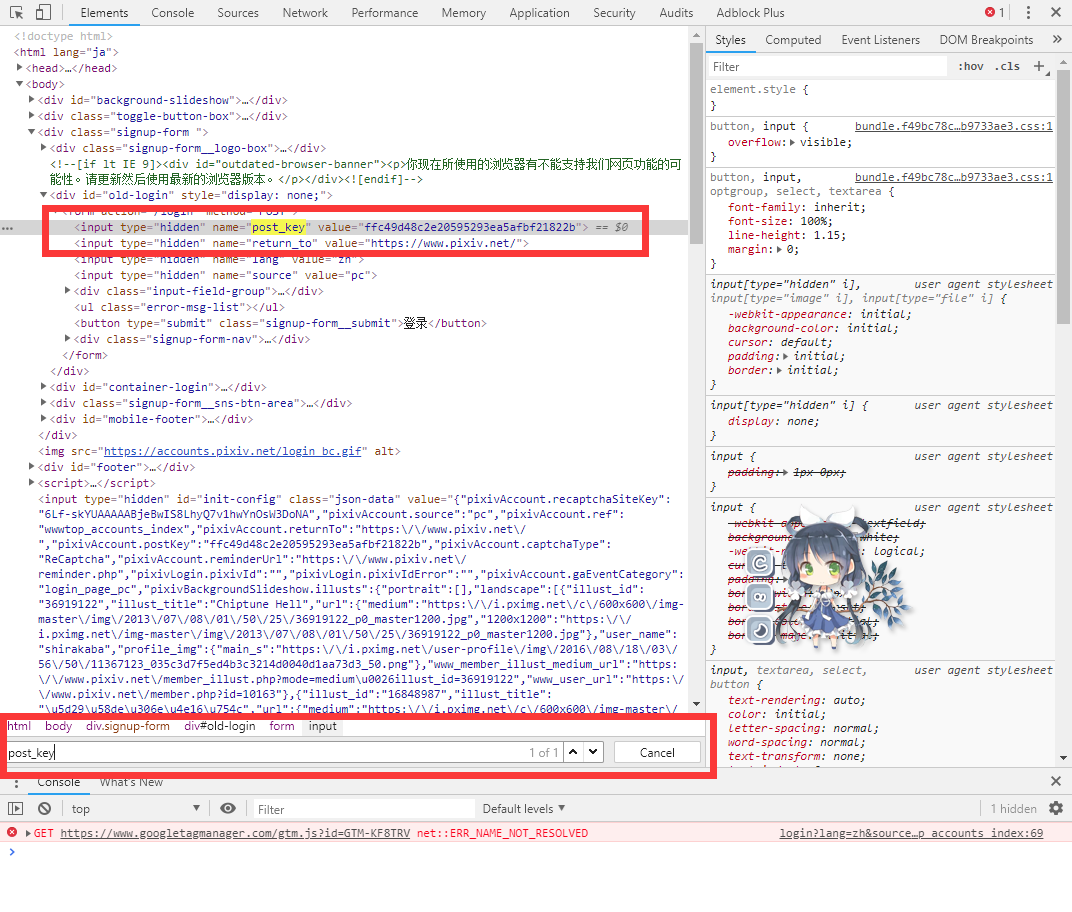
有自知之明的人早就找出来了,回到登录界面一发暴力Ctrl+F搜索输入post_key完美搞掂。 :huaji:
ojbk,可以捕获post_key了,接下来就是模拟登陆的代码了,其代码如下:
print("登陆( ̄▽ ̄)/")
pixiv_id=input("pixiv_id:")
pixiv_password=input("password:")
return_to="https://www.pixiv.net"
post_key_html = se.get("https://accounts.pixiv.net/login", headers=headers)
post_key_soup = BeautifulSoup(post_key_html.text, 'lxml')
post_key = post_key_soup.find('input')['value']
#其实这里不用findall也是可以的,毕竟post_key就是在第一行,当然严谨点的你可以改一下
data = {
'pixiv_id': pixiv_id,
'password': pixiv_password,
'return_to': return_to,
'post_key': post_key
}
#其实return_to不用写也是可以的,最主要id、password、post_key一定要上传上去
#print (data)
data_re=se.post("https://accounts.pixiv.net/api/login?lang=zh", data=data, headers=headers)
#保存cookies,以便下次使用
data1['device_token']=data_re.cookies['device_token']
data1['PHPSESSID']=data_re.cookies['PHPSESSID'][title]搜索界面[/title]
在搜索界面打上你需要找的东西,哪怕是个可爱的女♂孩子的名字。
输入回车。可以看到右边有输出了,点击进去一看,这搜索的请求DATA也不难构造。
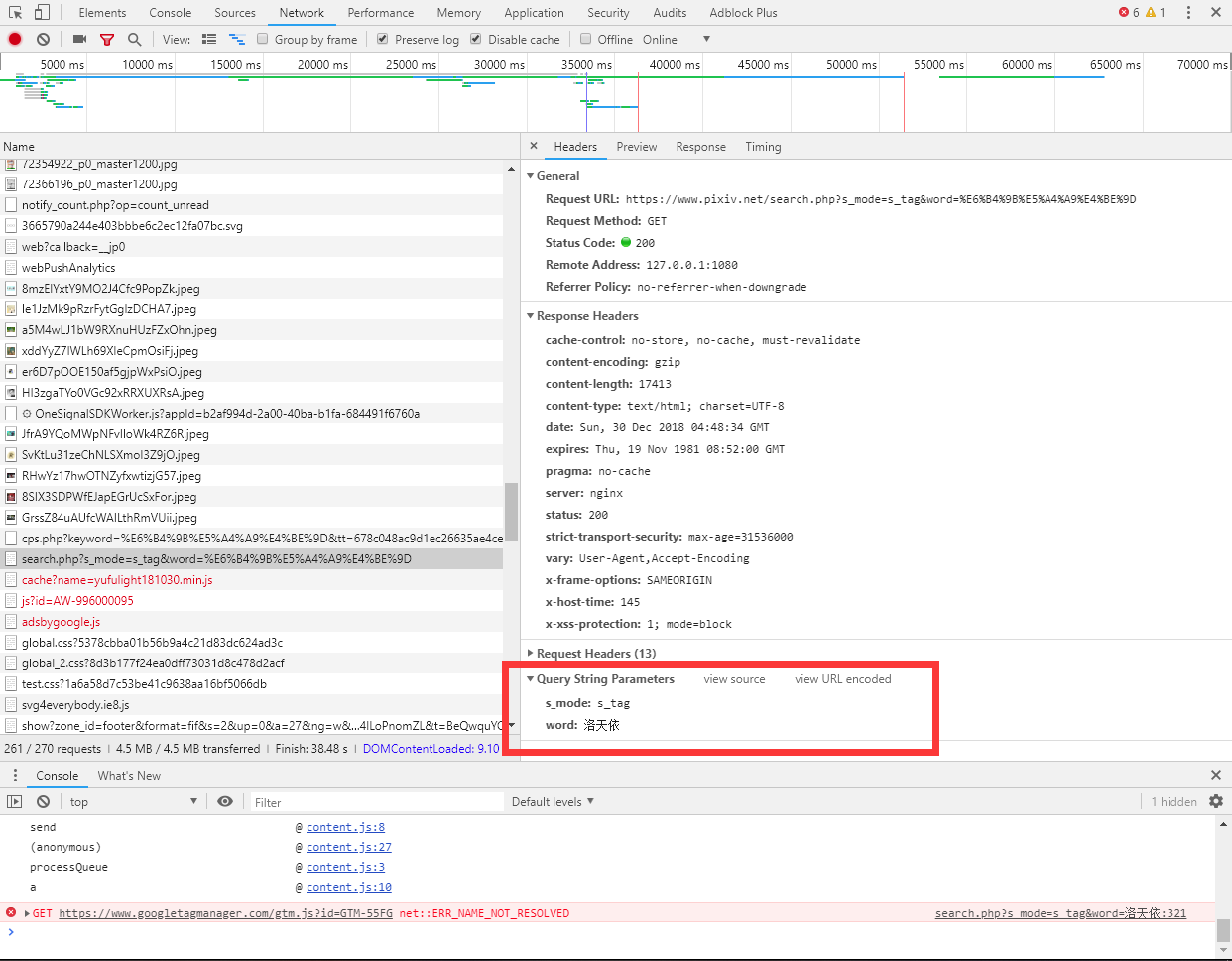
接下来也就十分有趣了。
我还记得以前P站有个固定的CLASS类专门放置作品的链接以及各种信息数据的。后来第一代爬虫出事故后,当时也不知道是什么原因,以为是传输问题。打开VS调试,发现BeautifulSoup4抛出错误:不存在此CLASS类名称。wdf? :huaji12:
后来发现CLASS类的名称都改了,还一堆我看不懂的乱码?而且一段时间后就变了,还是随机的?这怎么获取啊qaq
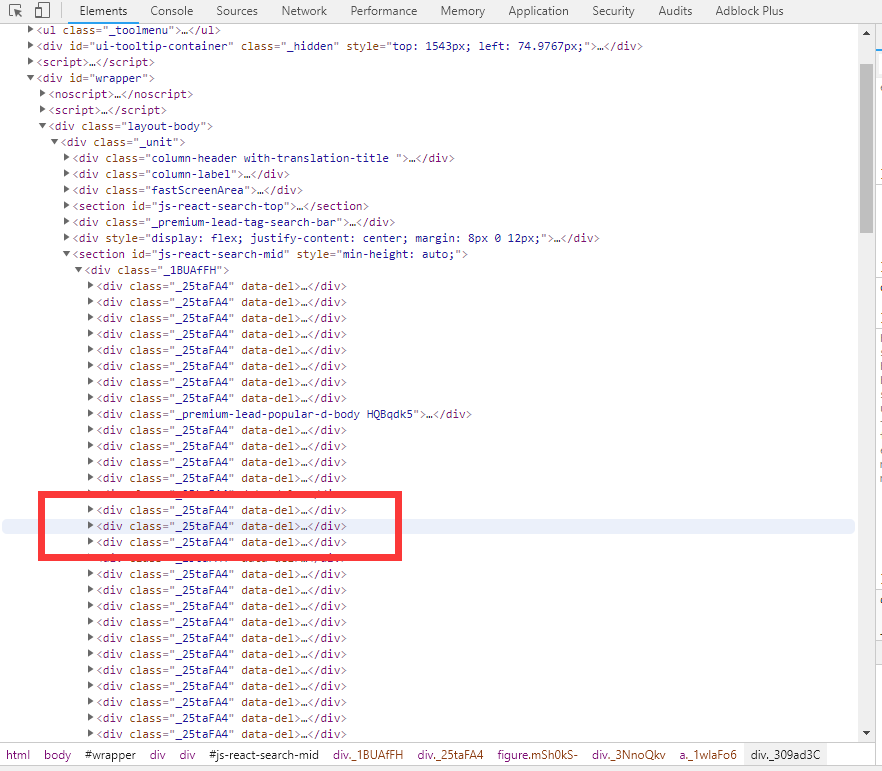
当时进过各种摸索,开始认为是脚本向服务器请求搜索数据然后再嵌入网页的,结果刷新调试了半天没有发现 :pen:
后来受不了,就把网页源复制到Notepad++,再来一发暴力Ctrl+F搜索,结果差点把我吓死 :huaji16:
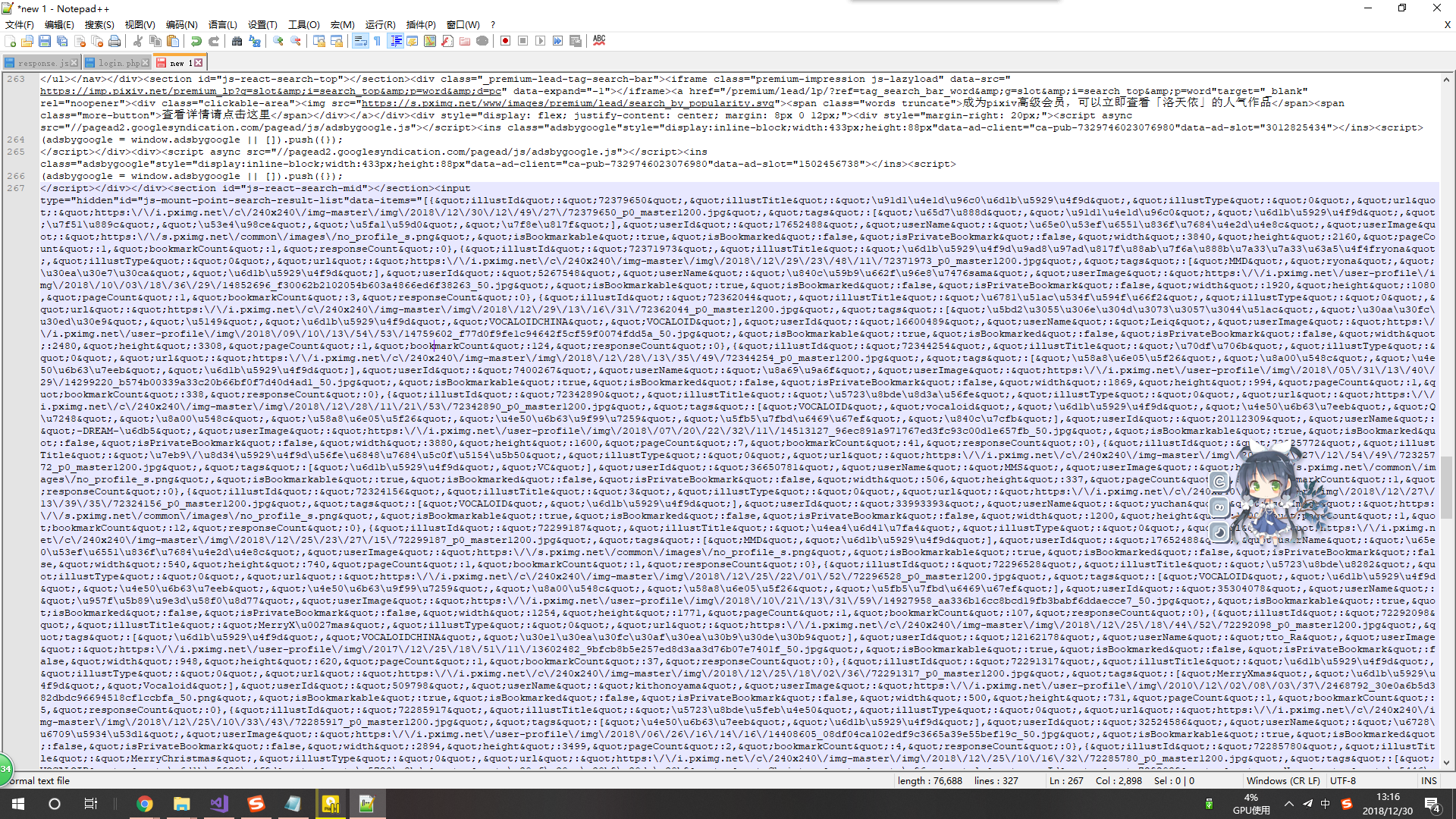
居然他用data-items属性保存了下来,格式还是JSON,然后脚本读取整理后再嵌入网页。
我感觉到了P站的程序猿为了防止爬虫程序付出的辛苦,然而没什么卵用:huaji13:
我还看见大佬还打算用动态加载搞掂这个东西,我想说一句真的不麻烦吗?
经过转码后窃取一块数据看,也不难发现结构。
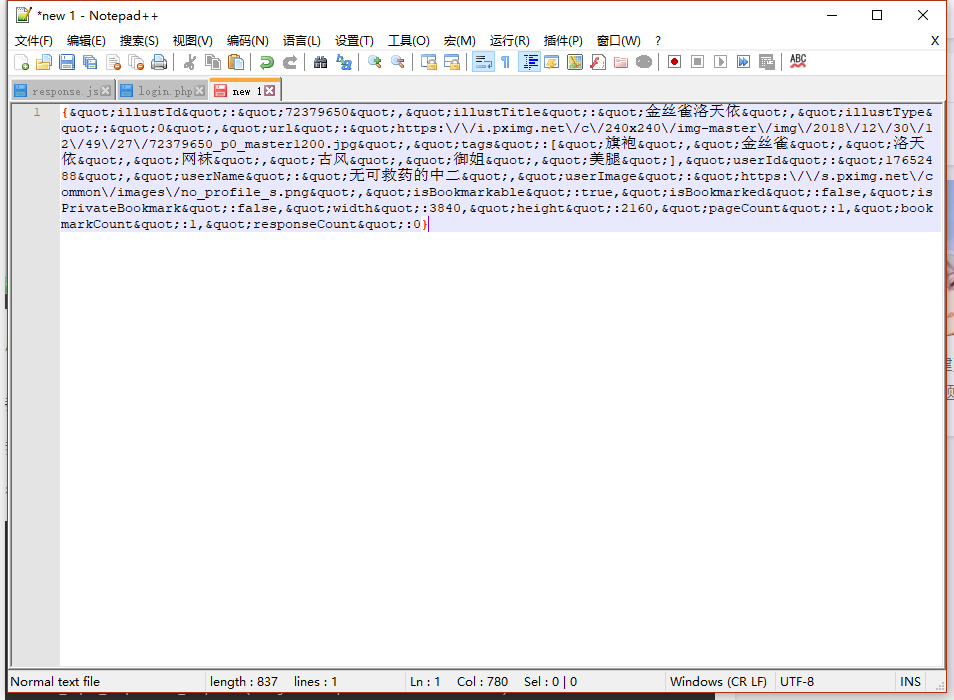
我们主要要获取的是illustId(作品ID)、bookmarkCount(赞或翻译过来叫书签计数?)、pageCount(该作品的页数),剩下的都不用处理了,毕竟有illustId了还拿不到作品? :huaji18:
得了,竟然知道这样了也就不难理解了。
dict1 ={'word':SearchName}
#得到你要搜索的人物
search_url="https://www.pixiv.net/search.php?s_mode=s_tag&"+parse.urlencode(dict1)
#这个是要获取的指定搜索页
#search_url="https://www.pixiv.net/search.php?s_mode=s_tag&"+parse.urlencode(dict1)+"&order=date_d&p=3"
#发送请求
search_html = se.get(search_url, headers=headers,cookies=cookies_data)
search_soup = BeautifulSoup(search_html.text, 'lxml')
#获取数据
search_input_soup=search_soup.find(id='js-mount-point-search-result-list')
data_compile=re.compile("{.*?}",re.S)
data=re.findall(data_compile,search_input_soup['data-items'])
#print (data)
#解析
print("正在解析搜索界面(~ ̄▽ ̄)~ ")
#为了防止P站有防盗链机制而做的这个,保存搜索的URL
pixiv_href_data.search_url=search_url
for rec_data in data:
text = json.loads(rec_data)
#print (text)
#print (text["illustId"])
#print (text["tags"])
#print (text["illustTitle"])
#print (text["bookmarkCount"])
#pageCount
#过滤,是否有水,其实这个还不算精准,只是粗略过滤
if(int(text["bookmarkCount"])>3):
#加入到数组
pixiv_href_data.illustId.append(text["illustId"])
#pageCount
pixiv_href_data.pageCount.append(int(text["pageCount"]))
#每一个符合条件的作品都会加个FLAG标记,方便下面二次处理
pixiv_href_data._return.append(0)
else:
print("根据书签计数算法已经过滤一个作品(`・ω・´)作品ID为:"+text["illustId"])
#转到standII再解析
standII()下面是standII函数内容,会有比较具体的注释:
def standII():
#读取该下载页有多少作品
a=len(pixiv_href_data._return)
for number in range(0,a):
#遍历
if(pixiv_href_data._return[number]==0):
#其实这个标记是给多线程操作的,判断这个作品是否被另外一个线程解析
pixiv_href_data._return[number]=1
if(int(pixiv_href_data.pageCount[number])>1):
#判断作品页数,分别进入该进的函数
#print (downloadfile_data)
#多图作品来这里
#把作品ID送入函数
manga(pixiv_href_data.illustId[number],downloadfile_data)
else:
#单图作品来这里
medium(pixiv_href_data.illustId[number],downloadfile_data)[title]单图爬取[/title]
下面是单图解析过程:
果然还是逃不过CLASS类名称的破操作。
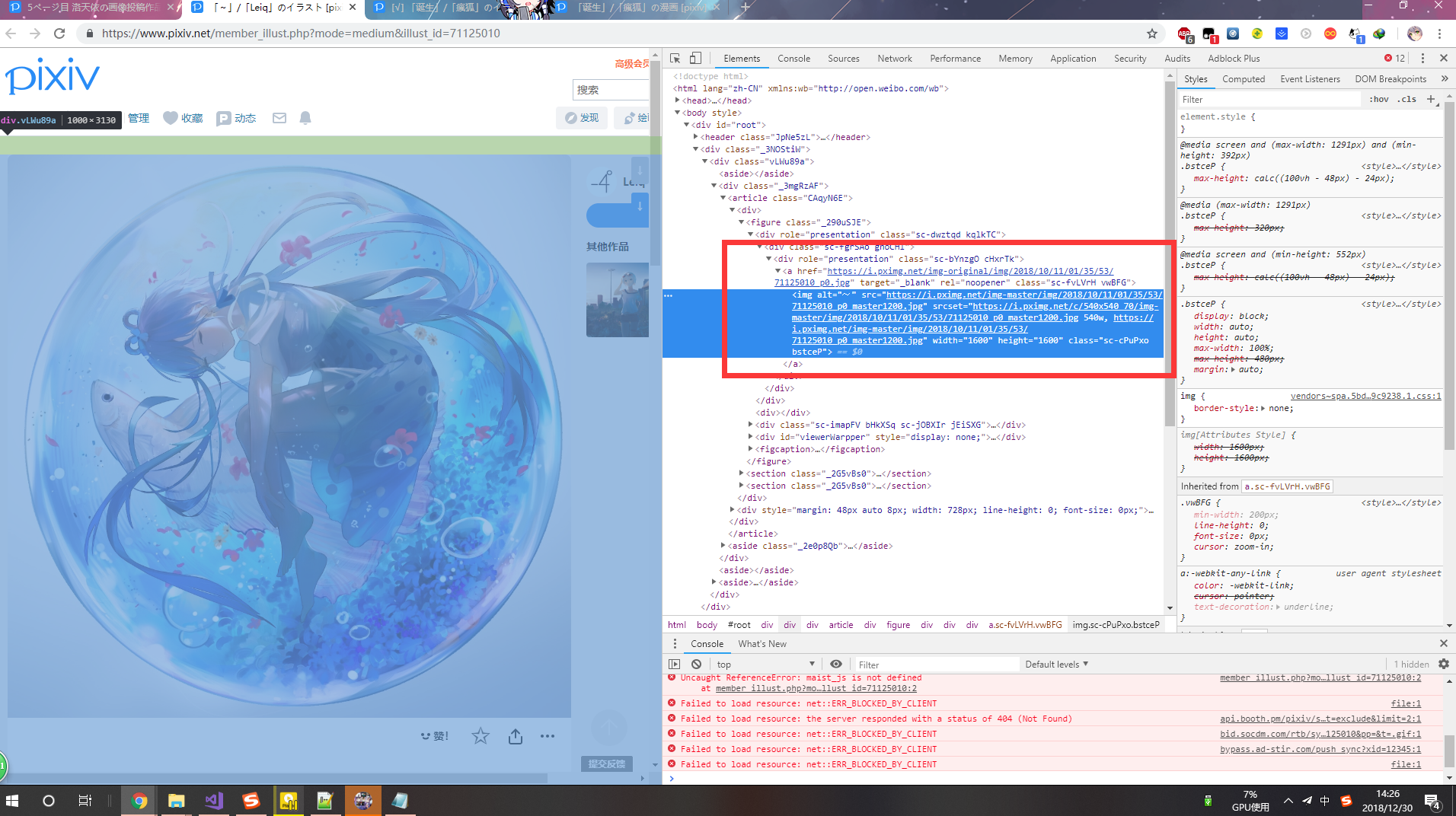
既然在搜索界面已经知道这种操作了,也不需要我说了 :huaji13:
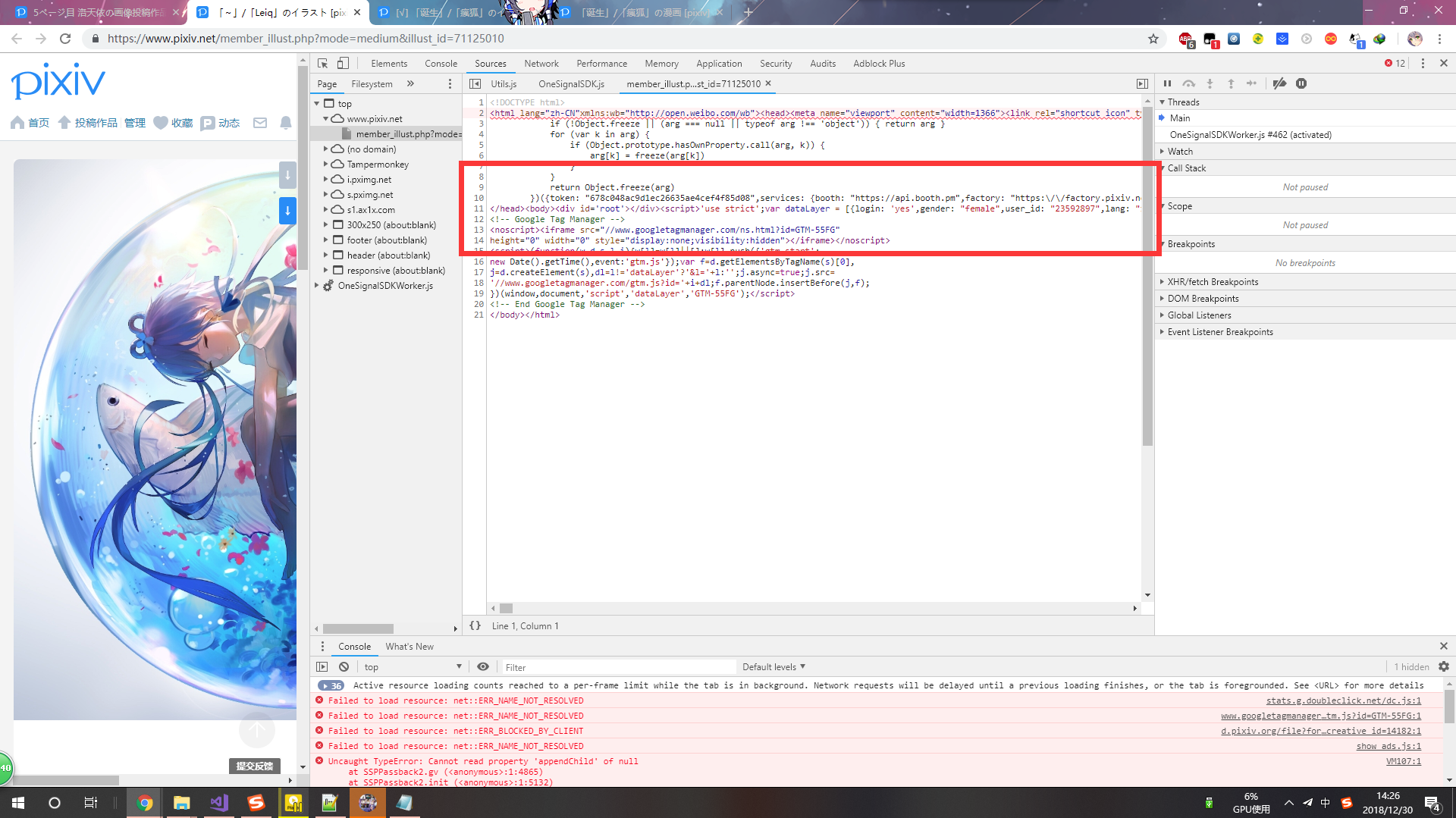
其实呢......前不久重新摸鱼了一下,发现P站居然有API。 :huaji15:
说明一下,其实是很久之前我摸出的API,不知道现在是P站发现了,现在在作界面上没调用这个API了......
目前(截止至2019年1月14日22:27:26)我调用这个API还是能正常运行。
调用方法:https://www.pixiv.net/ajax/illust/+illustId
说明:illustId是作品的ID,直接调用即可。
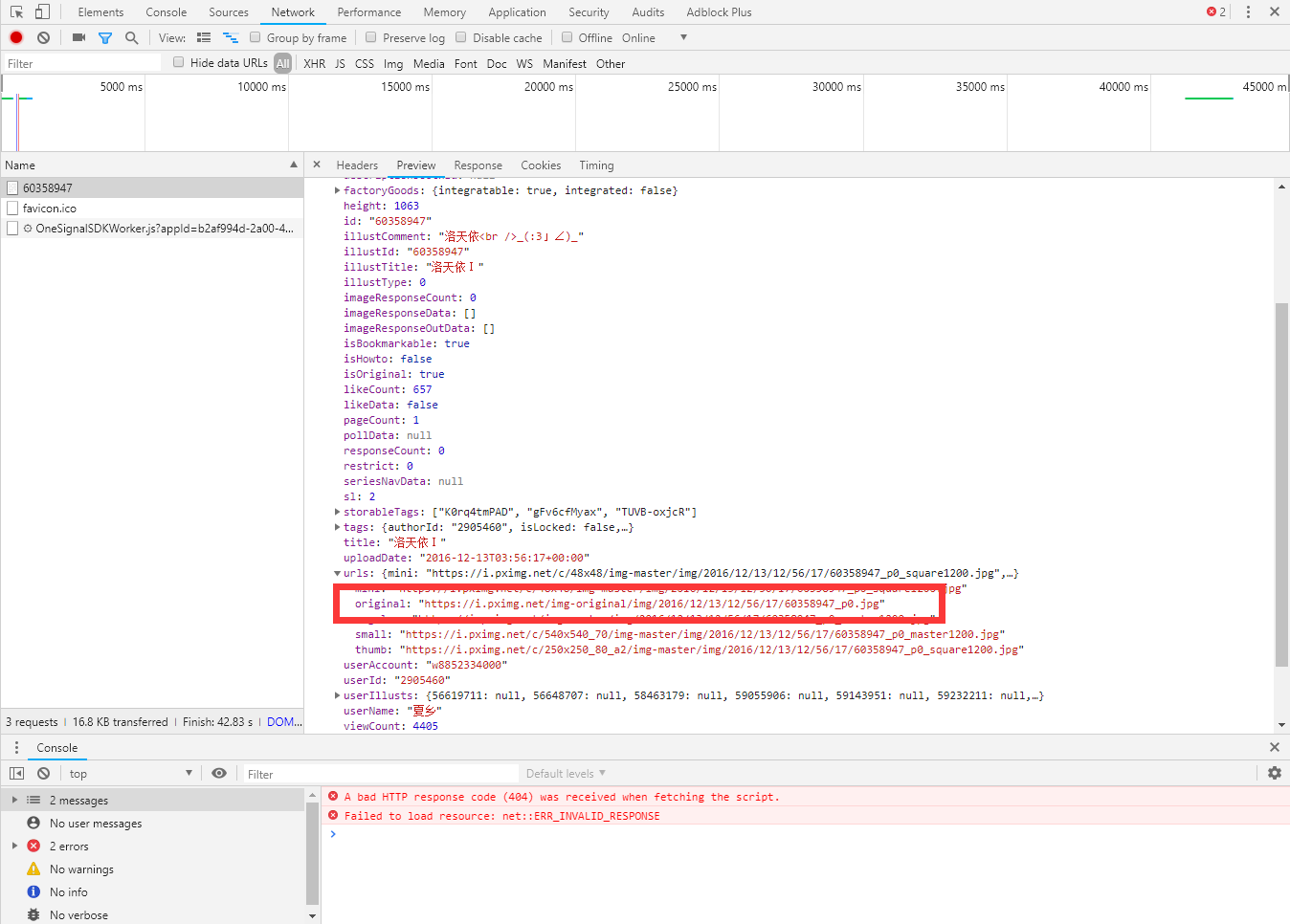
提取这个地址就可以了。
不过要我硬是要讲怎么找我也说说吧,刚刚在P站的手机端发现了这个类似API,调用方法不一样。
先等我歇一会再讲吧。咕!
下面是medium函数代码:
重要的事情再强调第一遍:P站有防盗链机制,假如返回头Referer不带之前作品的URL,P站会给你403错误的。
def medium(illustId,downloadfile):
headers = {
'Referer': 'https://www.pixiv.net',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
medium_url="https://www.pixiv.net/member_illust.php?mode=medium&illust_id="+illustId
headers["Referer"]=medium_url
#print (illust_url)
illust_url="https://www.pixiv.net/ajax/illust/"+illustId
try:
illust_html = se.get(illust_url, headers=headers,cookies=cookies_data)
except BaseException as e:
print("读取网页发生错误(;д;)错误信息为:", e)
return
#print (member_illust_html.text)
illust_json = json.loads(illust_html.text)
#解析json
#print (illust_json['body']['urls']['original'])
download(illustId,illust_json['body']['urls']['original'],headers,downloadfile)[title]多图爬取[/title]
问题来了,怎么处理多图数据? :huaji14:
之前在单图爬取的时候说过那个API,但是问题是输入多图图的作品的ID时候发现只能返回第一张图的地址......
还是想想办法吧。 :han:
依然还是一个破操作,但是我发现点“查看全部”时候,发现CLASS类的名称固定了 :huaji2:
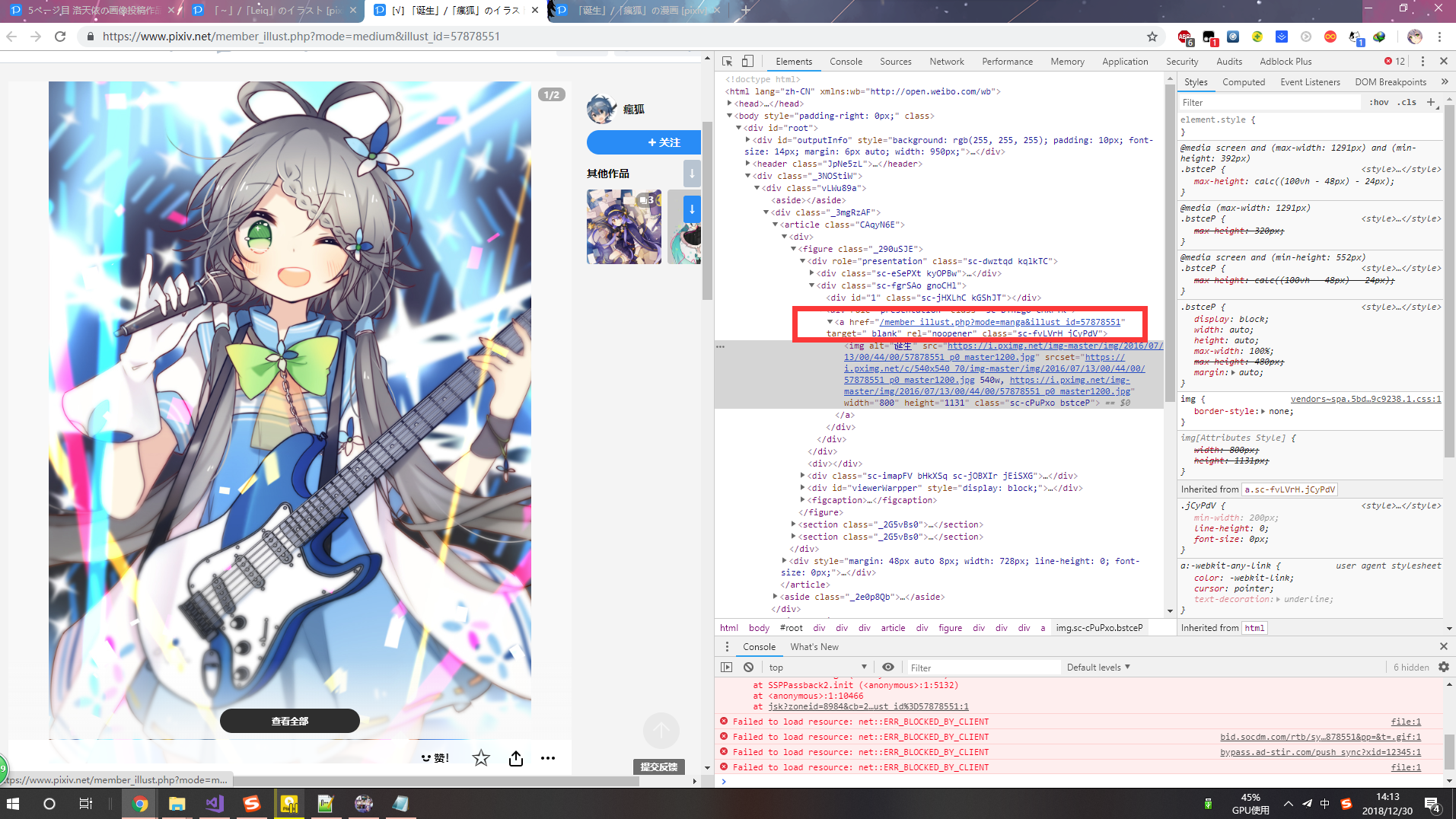
这就好办了 :huaji2:
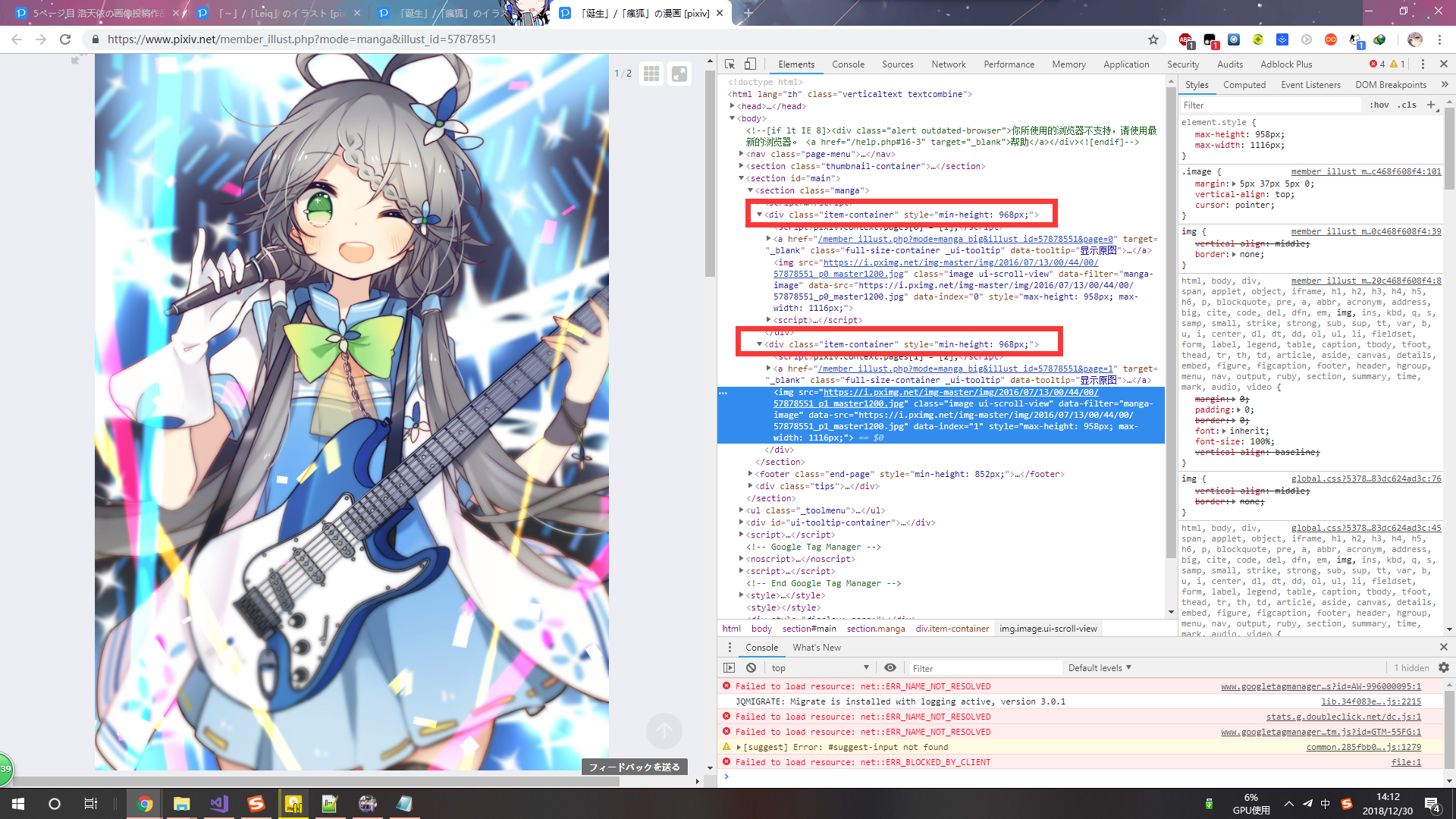
我猜应该是P站程序猿不行跟你们玩了 :huaji13:
重要的事情再强调两遍:P站有防盗链机制,假如返回头Referer不带之前作品的URL,P站会给你403错误的。
下面是代码:
def manga(illustId,downloadfile):
#初始化headers头,下载的时候得带上这个,P站有防盗链,不然就会出现404
headers = {
'Referer': 'https://www.pixiv.net',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
}
print("发现此作品是多图,作品ID:",illustId)
illust_url="https://www.pixiv.net/member_illust.php?mode=manga&illust_id="+illustId
headers["Referer"]=pixiv_href_data.search_url
#防止翻车
try:
member_illust_html = se.get(illust_url, headers=headers,cookies=cookies_data)
except BaseException as e:
print("读取网页发生错误(;д;)错误信息为:", e)
return
#print (member_illust_html.text)
#解析
headers["Referer"]=illust_url
item_container_soup = BeautifulSoup(member_illust_html.text, 'lxml')
manga_image_soup=item_container_soup.find_all('div', attrs={'class', 'item-container'})
for manga_image_soup_data in manga_image_soup:
data_src=manga_image_soup_data.find('img')['data-src']
#print(data_src)
#下载,传入作品ID、图片路径、headers、和下载路径
download(illustId,data_src,headers,downloadfile)[title]下载操作[/title]
下载函数代码:
重要的事情再强调要强调三遍:P站有防盗链机制,假如返回头Referer不带之前作品的URL,P站会给你403错误的。
def download(illustId,data_src,headers,downloadfile):
#切割文本,取文件名
name_compile=re.compile(illustId+'.*',re.S)
name=re.findall(name_compile,data_src)
#print(name)
try:
#下载
html = se.get(data_src, headers=headers)
except BaseException as e:
print("下载图片发生错误(;д;)错误信息为:", e)
return
img = html.content
title=downloadfile+'\\'+name[0]
print("作品ID:"+illustId+" 作品下载到:"+title)
with open(title , 'ab') as f:
#乌拉!!!!!!!!!
f.write(img)好了,还有动态图的解析没搞,之前也写了关于动态图的代码,然后一次格式化系统没备份,没了(;д;)
[title]总结[/title]
目前整个爬虫过程不是十分难,运用了一些基本的爬虫操作和文本切割。就是中间有你最想不到的操作2333。
其实可以写个多线程下载的,也并不难,就在搜索后面直接创建多线程。包括一页一页下载,在前面加个which慢慢玩。但是多线程下载......目前按照国内这种情况......就算了吧,我怕你都进不去。 :huaji23:
还有个BUG,也就是程序运行的时候并没有判断COOKIES是否还有效,造成无法读取bookmarkCount,导致解析时候全部过滤掉,有空我一定修复。(咕!)
本来我想用CLASS类封装整个代码,但是作为学生党没时间再改了qaq.......
代码已经上传到github :点我传送
求大佬围观,求star!乌拉!!!! :huaji13:
[title]修复日记[/title]
2019年1月14日21:30:16:
在重新登录时候,写入配置时使用了with open("Setting.txt", 'ab') as f: ,即写入文件的模式为ab(翻译过来就是写入文件时候新的内容将会被写入到已有内容之后),导致旧的JSON数据存在而新的JSON数据在后面,程序重新运行JSON会解析失败,在data1 = json.loads(str(text))处运行报错,修复后代码改为with open("Setting.txt", 'wb') as f: ,写入文件的模式为wb(翻译过来就是从开头开始编辑,即原有内容会被删除),这样覆盖了原来的配置,完美解决。
2019年1月14日22:37:18:
单图解析的作品使用了API,简直暴力。

文章评论
大佬牛逼
@路人 C#大佬你好 :huaji2:
dalao NB,但是发现pixiv现在登录需要recaptcha了,模拟登录好像失效了
@ddhello recaptcha简单 用selenium登陆后复制cookies到一个Session ok了
@ddhello 的确是,现在只能手动获取COOKIE解决了 :han:
兄弟你是不是把api打成aip了2333
@Jarao 哈哈哈现在才发现,而且自己读成AIP顺口还觉得没什么不对[doge]
用pixivpy啊,python的库,直接验证了2333
@TheWanderingCoel 我看了一下确实简单粗暴,就是功能少(比如拉取排行这类的),可惜现在P站被ban了,不过还是有办法的 :hu:
@洛水.山岭居室 排行应该是有的,我还拿Qt5重写了一个 OωO
很好奇单图爬取那里是怎么找到api的 可以大概讲一讲嘛 (/ω\)
@Rainym00d 网上大部分也有教程,如果是我的话简单方式按F12进开发者工具里面的Network去找,可以过滤一下条件选择XHR,一个一个翻翻看,虽然效率低但是还算可以 ヾ(´・ ・`。)ノ
就比如上面说到的API,你可以去试试看,你就会发现返回的数据里面的数据可以发现出里面有返回的图片地址,而且调用方式也很明显 φ( ̄∇ ̄o)
@洛水.山岭居室 感谢? 我在看的时候 发现多图爬取那里也可以直接调用api json文件里有个pageCount 这里记录了页数 然后可以在url里更改p0后面的数字就行了 这样子可以把多图爬取和单图爬取合并了
第一次用这个api好爽 :huaji2: 之前写的时候一直都是bs4解析html文本 眼都花了
博主介意加一下联系方式吗 不介意的话可以通过邮箱告知我一下
@Rainym00d :huaji: 我博客右边不是没有吗?
天依好评
@锦依卫 :huaji: :ok: 当然好评
(还有你邮箱有毒吧邮件发不过去)
老哥 能加个好友嘛?我最近也在爬pixiv 但是出问题了,想向你请教一下
@虚幻 直接在这里说也无碍,有什么快提吧。
就是 你是怎么获取到图片的text的 你的那个代码还能用嘛? 还有现在还能模拟登陆吗?我模拟登陆获取到text,里面没有图片的信息
@虚幻 pixiv现在登录需要recaptcha了,你是用的是selenium去获取吗?
@洛水.山岭居室 我当时是用request.session模拟登陆的
@虚幻 如果按照上面的代码应该是没什么错误的,cookie这类你传递上去没
@洛水.山岭居室 老哥 你这个代码能跑吗?能跑的话 我就研究研究你的代码.
老哥 你这个博客是用什么搭建的?
老哥能说一下你的技术线嘛?
@虚幻 代码很久之前了,现在B站也换完API了。
现在在github上的代码估计都是手动获取cookie实现登陆的(从浏览器复制一份)
博客用WordPress搭建的。
@洛水.山岭居室 哦哦 好的 感谢老哥 我再好好学习学习
大佬,我请教个问题可以吗?
我用requests模拟登陆,获取了cookies然后
用requests.get带cookies请求日榜网址
可是打印出来的网页源码显示我没登录成功,是什么原因呢?
我post的数据应该都没什么问题,post_key也有了,可就是登录不上去
@夏夕空 难道你没有看一下返回的数据吗,应该是拒绝掉了
一定要翻墙吗?呜呜呜
@高&冰 你可以试试绕过SIN审查(旁路阻断)达到这个目地。
更具体的过程我就不细说了。
@洛水.山岭居室 !
@洛水.山岭居室 sni